How to migrate your API and still be friends with your fellow client developers
One of the best things about working in Deliveroo Engineering is that we have the opportunity to work on a great ever-changing product, which means we are constantly evolving, improving and facing new challenges. One of the main problems we have right now, which is a great problem to have, is the fact that we have grown so much that our monolithic application can’t hold everything in just one place anymore.
That is why only 5 years after Deliveroo’s inception, we’re already decomposing our monolith into several services. It is the responsibility of every team to make this migration as smooth as possible, because we believe reliability is fundamental.
Smooth Migrations
One of the responsibilities of my team is to maintain the API that helps customers and Customer Support agents to solve issues related to orders. Part of this API is still in the monolith so we have recently started to migrate the remaining endpoints into our own service. Since this migration will affect our web and mobile clients, we need to be sure that the responses from our service match exactly the ones from the monolith. We’re keen to make sure our services are always reliable, so we came up with a plan to make this migration as smooth as possible.
This is how we are doing it.
Step 1: proxying
The first step was a quick one. We started by creating new endpoints in our service that act as proxies between the clients and the monolith.
By doing this, clients can switch to the new endpoints whenever they are ready and they won’t need to change anything other than the URL they are calling. Because we are returning exactly the same response as they used to get, they can also use a feature flag to go back to the previous call if something goes wrong, without requiring further changes.
Step 2: comparing
Next, we started building our own functions to generate the same output that the monolith generates at the moment. Once we have our new generated response, we compare it with the one obtained from the monolith, tracking the results in our monitoring system. Whenever we get a response that is not exactly as expected, we log both responses in order to review them later and understand what are we doing different. The next step is to return to the clients the response that we got from the monolith, since we still don’t have a version that is 100% correct.
You are probably thinking: “isn’t this solution going to make the proxy very slow?”. Well, not really. We have implemented generation and comparison in an asynchronous task. Thus, as far as the clients are concerned, we are still just proxying the response from the monolith to them. The customer flow won’t be delayed in any way by the comparator. Another advantage is that, if something goes wrong inside this task, the clients won’t be affected.
In a nutshell, it looks something like:
def proxy
monolith_response = get_response_from_monolith
if scenario_already_implemented?
ComparatorWorker.perform_async(monolith_response)
end
render json: monolith_response.body, status: monolith_response.status
end
Step 3: observing and reiterating
Once our comparator is up and running, we just need to sit down and wait…
Not quite! First of all, we updated our android application to start making requests to our new endpoint, so that we could observe which scenarios were properly handled and which ones were not. Of course we didn’t get it all perfect at the first try, because this is indeed a very complicated endpoint, so we expected to see some differences.
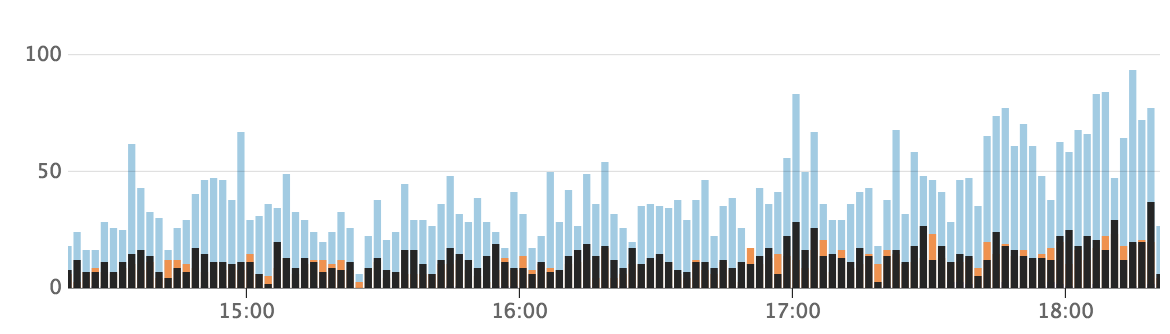
Here is an example of the responses that match exactly the monolith response (blue) versus the responses that are slightly different (orange). The results in black are the ones we have not implemented.
Whenever we see a response that doesn’t look as expected, we review it and fix it if necessary. Note that some differences might be correct, like the response might contain a URL that used to point to the monolith and now needs to redirect to the new service.
Step 4: switching
This step will come into play once we are happy with the results we are generating. Then, we’ll switch our endpoints so the data that the clients receive will be our new generated response and not the one from the monolith. We’ll keep the comparators running for a few more days to be sure that we have not missed anything, but we won’t proxy the responses anymore.
Step 5: cleaning up
Only when we are sure that everything works as expected, we’ll completely remove the calls to the monolith and the comparator code.

Feature flagging
As mentioned earlier, we decided to implement this comparator asynchronously so we don’t impact the user flow. But all precautions are not enough when you want to be sure that you are always reliable. So we also decided to use feature flags to be able to turn this feature on and off whenever needed.
In this case we used two types of flags:
- Mobile/web clients have a flag to decide which URL they should use. Then, if anything goes wrong with our service, they can still call the monolith directly. Since we return the same response, they won’t have any problem.
- The endpoints in our service also have a flag to enable or disable the comparator, so we can turn it off in case we detect high traffic or any other issues we might be causing. And again, because this happens in an asynchronous task, the proxy will return the same results regardless of the flag.
Now there is just one big question left… who is going to volunteer to clean up the code in the monolith?
About Erika Moreno Sierra

I’m a engineering manager here at Deliveroo.
I was born in Spain, where I studied Computer Engineering. Soon after finishing, I moved to Dublin for a couple of years. The plan was to go back to Madrid after that but instead I ended up in London. My family has stopped asking me when I will be back.
I used to be a Python developer but now I’m learning Rails. I don’t know what will be next, in the end the language is just a tool!
You can find me on Twitter as @erikamsierra