Improving Stream Data Quality With Protobuf Schema Validation
The requirements for fast and reliable data pipelines are growing quickly at Deliveroo as the business continues to grow and innovate. We have delivered an event streaming platform which gives strong guarantees on data quality, using Apache Kafka® and Protocol Buffers.
Just some of the ways in which we make use of data at Deliveroo include computing optimal rider assignments to in-flight orders, making live operational decisions, personalising restaurant recommendations to users, and prioritising platform fixes. Our quickly expanding business also means our platform needs to keep ahead of the curve to accommodate the ever-growing volumes of data and increasing complexity of our systems. The Deliveroo Engineering organisation is in the process of decomposing a monolith application into a suite of microservices.
To help meet these requirements, the Data Engineering Team (which I’m part of) has developed a new inter-service messaging framework that not only supports service decomposition work but also helps quench our thirst for analytical data. Because it builds on top of Apache Kafka we decided to call it Franz.
Franz was conceived as a strongly typed, interoperable data stream for inter-service communication. By strictly enforcing a requirement of using Protobuf messages on all Kafka topics, our chosen design guarantees reliable and consistent data on each topic, and provides a way for schemas to evolve without breaking downstream systems.
This article describes how we came to implement a flexible, managed repository for the Protobuf schemas flowing on Franz, and how we have designed a way to provide a reliable schema contract between producer and consumer applications.
The Need for a Structured Message Format
A key requirement of our centralised event streaming platform is resilience and one step towards achieving this is providing guarantees about the structure of messages and data types within those messages. These guarantees mean consumer applications can have expectations of the format of the data and be less vulnerable to breaking due to corrupt messages. Another important aspect for resilience is being able to update the data model without breaking clients that are depending on a different schema version, which means ensuring we have backwards and forwards compatibility.
Our reasoning about these requirements came from previous experience of sending JSON over streams, with accidental or deliberate changes causing breakages. While there are some ways to give greater guarantees for JSON, such as JSON Schema, these still leave a lot to be desired, including a lack of well-defined mechanisms for schema evolution, not to mention the sub-par encoding and decoding performance of JSON itself.
Deciding on an Encoding Format
The team began investigating the range of encoding formats that would suit Deliveroo’s requirements. The organisation makes use of many different programming languages, so it was paramount that our chosen encoding format be interoperable between those languages. This led us towards choosing a format that supports defining a schema in a programming language agnostic Interface Definition Language (IDL) which could then propagate the schema across to all the applications that need to work on that data. In addition to this, benefits such as binary serialisation (reduced payload size) and schema evolution mechanisms were aspects the team had worked with before on previous projects, and were keen to make use of again.
We quickly narrowed the choice of serialisation formats to three: Thrift, Protobuf, and Avro. We then proceeded to conduct an evaluation of these formats to determine what would work best for transmission of data over Kafka.
Thrift and Protobuf have very similar semantics, with IDLs that support the broad types and data structures utilised in mainstream programming languages. When conducting our evaluation, we initially chose Thrift due to familiarity, but in the end discounted this due to lack of momentum in the open source project. Thrift also left a lot to be desired in terms of quality, clarity and breadth of documentation in comparison to the other two formats. Avro was an intriguing option, particularly because of Confluent’s support for this on Kafka. Avro semantics are quite different to that of Protobuf, as it is typically used with a schema definition provided in a header to a file. Confluent Schema Registry removes this requirement by keeping the schema definition in an API and tagging each message with a lookup to find that schema. One of the other appealing aspects of Avro is that it manages schema evolution and backwards and forwards compatibility for you, by keeping track of a writers and a readers schema.
In the end Avro was discounted as not ideal for Deliveroo’s setup due to lack of cross language support. The thinking behind this was based on a desire for support of generated schema classes in each of Deliveroo’s main supported languages (Java/Scala/Kotlin, Go, and Ruby). Avro only supported the JVM languages in this regard. As it turns out, the way Confluent Schema Registry and Avro do support languages outside those with code generation support (through dynamic access to a schema through an API) turned out to be a feature we also wanted to support with Protobuf. To maintain maximum flexibility though, we’ve implemented both code artefacts for the main languages and a centralised repository for dynamic access.
Providing Guarantees on Graceful Schema Evolution
With our decision on Protobuf confirmed, we turned our attention to creating some extra safeguards around schema evolution. The repo that we maintain our Protobuf models in is used by many developers across different teams at Deliveroo, with models belonging to various services. The benefit of central management of these rules is that we ensure good data quality across all inter-service communication because the rules are defined once and used consistently. The Data Engineering team developed unit tests to enforce the rules, which run on every commit, and allow other developers to make changes to their models without needing to keep the rules at the front of their minds.
Before going into detail on the tests we implemented, it’s important to note that some aspects of graceful schema evolution are supported by virtue of Protobuf design. In particular, proto3 has done away with the concept of required fields (which made the decision not to use proto2 easier). With every field being optional, we’re already a long way into achieving backwards and forwards compatibility.
The Protobuf documentation outlines the rules for updating messages. A summary of those concepts in relation to stream producers and consumers follows.
Protobuf Properties That Support Forwards Compatibility
Forwards compatibility means that consumers can read data produced from a client using a later version of the schema than that consumer. In the case where a new field is added to a Protobuf message, the message will be decoded by the consumer but it will have no knowledge of that new field until it moves to the later version.
Fields that have been deleted in the new schema will be deserialised as default values for the relevant types in the consumer programming language. In both cases no deserialisation errors occur as a result of the schema mismatch.
Protobuf Properties That Support Backwards Compatibility
Backwards compatibility means that consumers using a newer version of the schema can read the data produced by a client with an earlier version of the schema. In a similar but reversed fashion as described above, fields that have been added in the newer version will be deserialised, but because the producer has no knowledge of the new fields, messages are transmitted with no data in those fields, and are subsequently deserialised with default values in the consumer.
Fields that have been deleted in the new schema will naturally require that any subsequent code that was in place to handle that data be refactored to cope.
Protobuf Rules That We Decided to Enforce
The remaining Protobuf requirements that are mandated to ensure data consistency are met by ensuring that the ordinal placeholders for each attribute are held immutable throughout a message definition’s lifespan. A Protobuf message definition consists of fields defined by a name, a type and an integer field number. The field number in particular is sacred, as this is what is actually transmitted in a serialised message (as opposed to the field name). All producers and consumers rely on this integer having a consistent meaning, and altering it can cause havoc if a consumer processes old data with a new understanding of what data belongs to a field number.
The tests we’ve implemented cover the following aspects:
- Field numbers must not be amended.
- Fields must not have their type amended.
- Fields that have been removed from a message must have an entry added to a reserved statement within the message, both for the deleted field and the deleted field number. This ensures that the protoc compiler will complain if someone attempts to add either of these back in to a subsequent version.
- Fields must not have their name amended (this would not break Protobuf compatibility, but we have the test in place to help maintain the evolvable schemas for JSON derived from Protobuf models).
The tests make use of the Protobuf FileDescriptor API and the protoc-jar library to generate single object representations of the entire message space, which can be used to track differences that arise between message versions within the scope of an individual pull request. While this doesn’t provide explicit guarantees that version 1 and version N of a schema will be compatible, it does facilitate this implicitly by setting constraints on the changes that an individual pull request would apply.
Providing Guarantees on Topic Schemas
The Confluent Schema Registry makes use of a centralised service so that both producers and consumers can access schemas and achieve a common understanding. The service keeps track of schema subjects and versions, as well as the actual schema details. This means that when a producer publishes data to a topic on Kafka, it registers the schema, and when that message is picked up by a consumer, it can use the attached identifier to fetch the deserialisation details from the registry.
Inspired by this, we set about creating a repository for schemas that would work well with Protobuf. In addition to this we came up with a way to provide even tighter guarantees around topics and schemas. Where Confluent Schema Registry provides a mechanism for knowing what this message means, we wanted a way to be sure that a consumer can trust a contract of the nature:
The first component employed to enforce these constraints is implemented in another Data Engineering team product; our Stream Producer API performs schema/topic validation before forwarding messages to Kafka. The second component is some mandatory metadata which is enforced within the API, but is defined in the Protobuf IDL. The metadata consists of Protobuf custom options. The custom option is defined once within a shared Protobuf file:
extend google.protobuf.MessageOptions {
string topic_name = 50000;
}
We then make use of this in all canonical topic schema definitions by including the topic_name attribute.
message Order {
option (common.topic_name) = "orders";
int64 id = 1;
// …
}
The full contract is achieved through a combination of the above topic metadata tying a topic to a schema, and a
separate mapping (within the Producer API configuration) between a publisher authentication key and that topic. If
a publisher serialises a message with a missing topic definition or mismatched definition in relation to the topic
being published to, the Producer API returns a 400 Bad Request to that publisher. By ensuring that all publishing
to Kafka is done via our Stream Producer API (topic ACLs prevent any other applications from publishing), we have
implemented a method to enforce the relationship between producers, topics, and schemas.
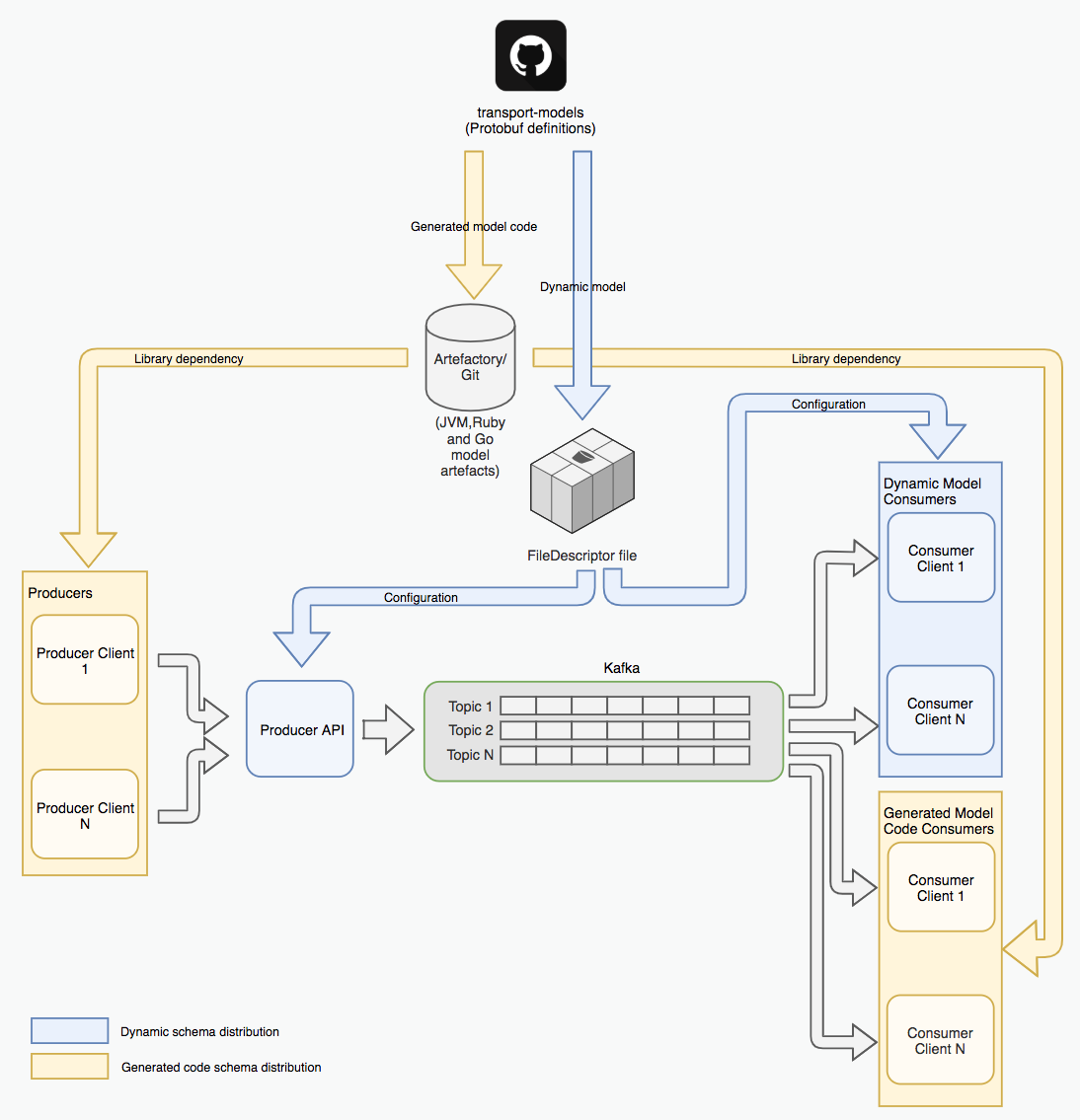
Managing Schema Artefacts and the Path Towards a Dynamic Registry
A key requirement for implementing central management of schemas is to minimise the burden for developers. While relying on generated schema artefacts can be useful in some instances (where one wishes to manage the use of a particular version of the schema within an application in a highly controlled manner), in other cases a client may be better off treating schema definitions more like configuration, available within the runtime environment. This is where Confluent Schema Registry excels, as schema definitions can be accessed without the need to include generated code within client applications.
We found our first requirement for this type of dynamic schema use case came from observing how awkward it was to keep the Producer API up to date with a constantly evolving Protobuf model repo. Initially, we had configured it so that the API required a library version update and re-release of the application every time the schema changed. This was quickly deemed too heavyweight to suit the pace of development.
To get around this, we implemented a method for the Producer API to quickly adapt to the latest schemas,
by again making use of the Protobuf FileDescriptor API. This method of schema distribution generates a master binary
schema file which can be loaded dynamically from Amazon S3. When a new schema version is committed to master, the
latest file is copied to S3, and then the Producer API is notified through its /refresh endpoint. This allows the
API to stay up to date without any downtime.
This new dynamic method now forms part of a two pronged approach for the distribution of schema information for clients, and gives developers a choice on which method suits them best. Since the Producer API use case transpired, we have since introduced some consumer applications which also make use of the dynamic model.
Summary
We have achieved our aim of building an event streaming platform that provides strong guarantees for consumer applications. The schemas for the messages flowing across the platform are owned by various teams within Deliveroo Engineering and we have provided ways to ensure that when those schemas evolve they can still be safely consumed. As the system has developed we have made improvements, from distributing schema artefacts in a variety of ways to embedding the topic mapping within schemas. These improvements have increased the overall workflow efficiency, and we expect more improvements of this nature to happen in future as we address new requirements.
About Tom Seddon

I’m a software engineer with a background in data. I studied computer science before starting my career in the world of analytics, and over the years found myself drawn to the engineering of data pipelines and analytical systems. Using and discovering technology to make data useful is what keeps me excited.