Real-Time Data Aggregation Using DynamoDB Streams
DynamoDB is great for quick data access, low-latency and scalability. However, one downside is that it does not support aggregation functionality like relational DB’s do. This is how we tackled this problem using DynamoDB Streams.
Table of Contents
- What Are ‘Favourites’?
- How is Favourites Data Stored?
- Our Goal
- Aggregating the DynamoDB Data
- Seeding the Aggregated Data Table & Keeping It In-Sync
- Conclusion
In this post I break down how we aggregate our ‘favourites’ data at Deliveroo. Our ‘favourites’ data is stored in DynamoDB and what makes the aggregation interesting is that DynamoDB does not support aggregate functions. The TL;DR is that we decided to use a DynamoDB Stream which invoked a Lambda function that updates an aggregate table. Keep reading for more details.
What Are ‘Favourites’?
In December 2021, we added the ability for our users to favourite restaurants. This is what that looks like:
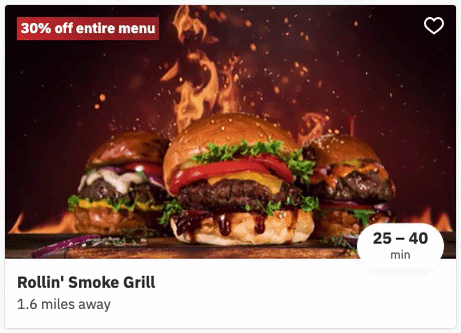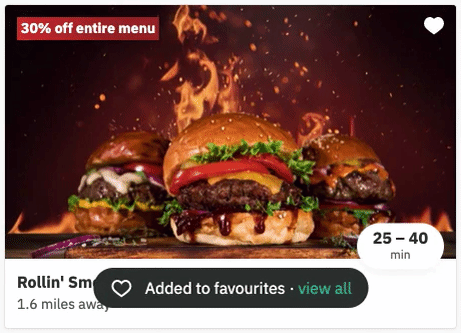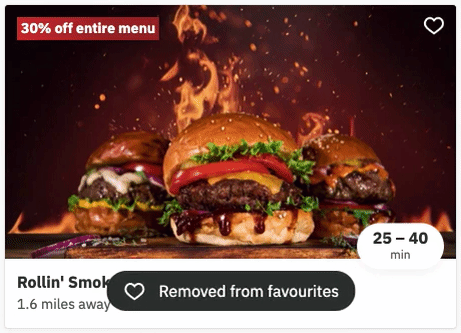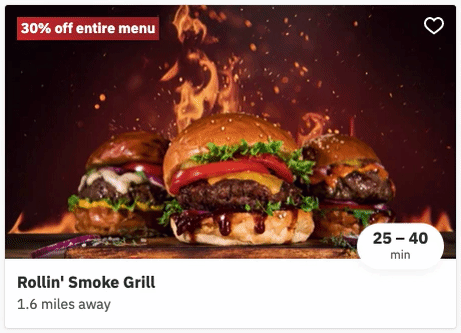
Clicking the heart favourites the restaurant, and clicking it again un-favourites the restaurant.
How is Favourites Data Stored?
A user’s favourite restaurants are stored in DynamoDB. Here is a simplified schema of our table:
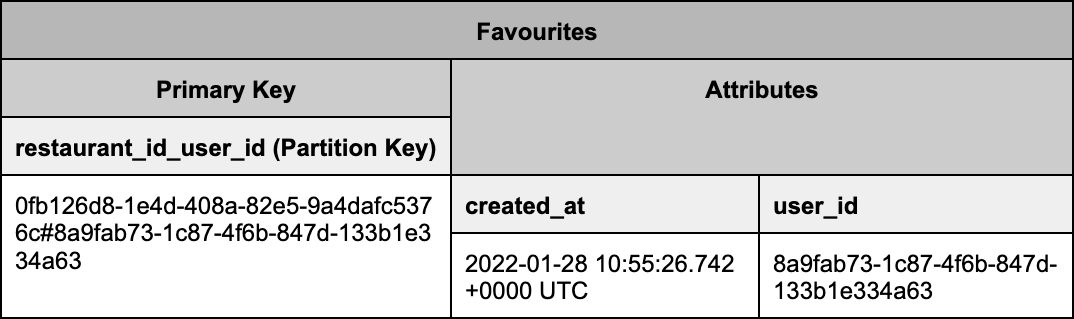
When a customer favourites a restaurant, a new item is inserted into Favourites. When the customer un-favourites a restaurant, the item in Favourites is removed.
Our Goal
We want to aggregate the favourites data (over all time) so that we can get the total favourite count per restaurant.
At the moment, this data is only required for this “most favourited places” list that appears on our customers’ feed:
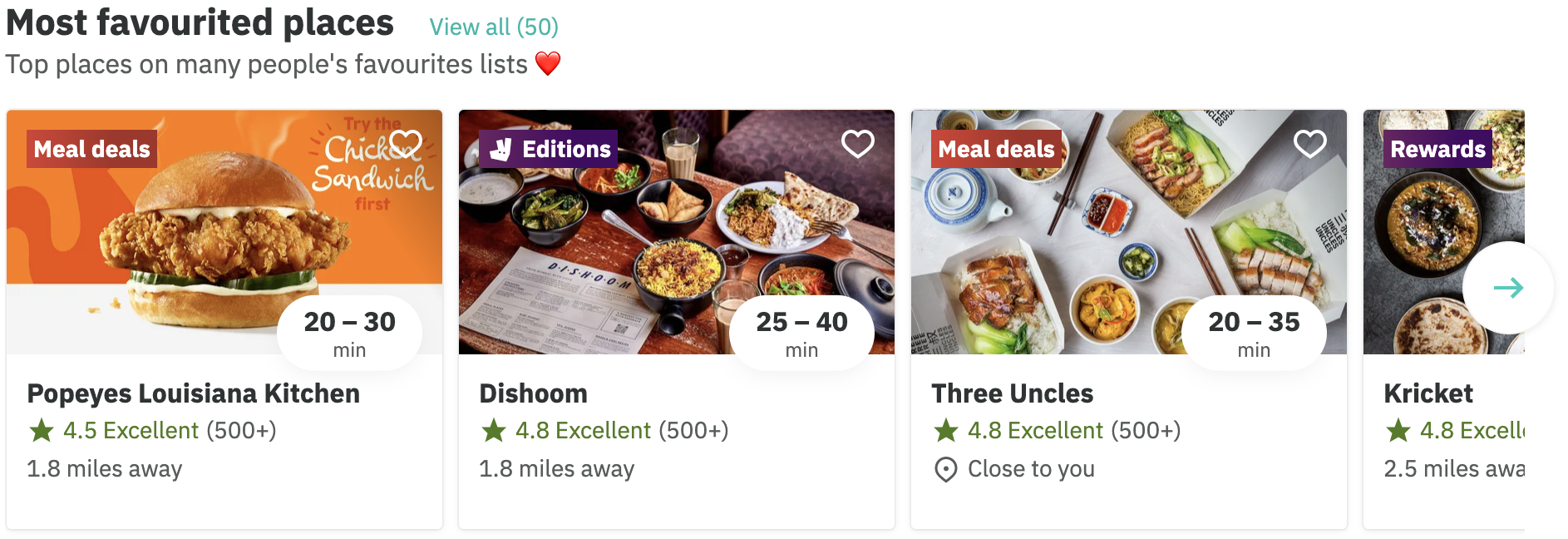
A list of restaurants ordered from most to least favourited
In the future, we’ll be using this aggregated data to explore and experiment with many new features, for example, displaying the total favourite count per restaurant:

Aggregating the DynamoDB Data
High-Level Design
As mentioned earlier, DynamoDB does not support aggregate functions. Therefore, there’s no magic SELECT SUM or GROUP BY clauses like in relational databases.
Instead, to aggregate favourites we implemented the following design (more details below):
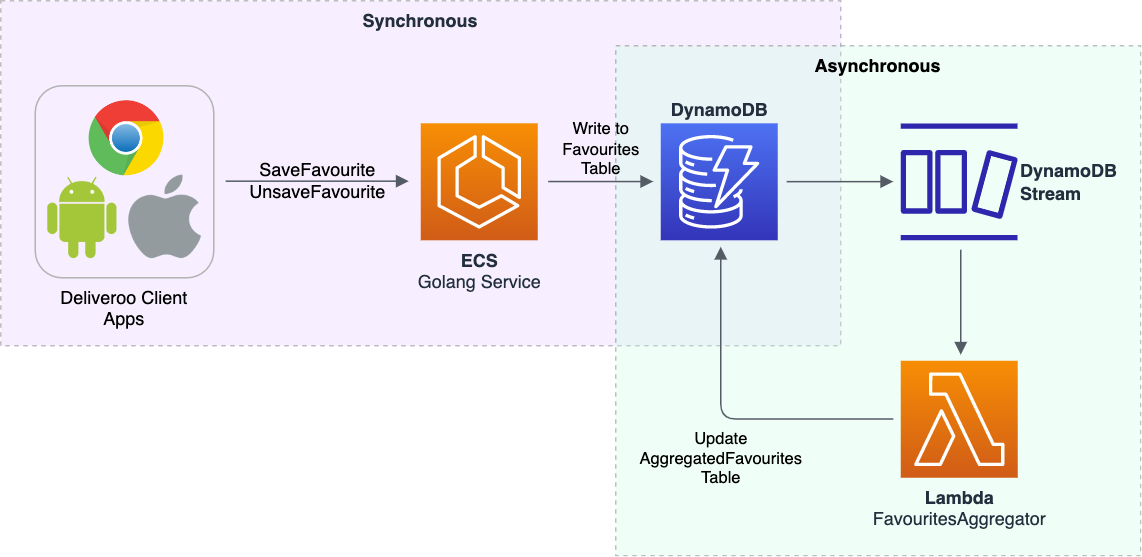
-
We created a new DynamoDB table to store aggregated favourites data with this schema (simplified for the sake of this blog post)

-
We enabled a DynamoDB Stream on the
Favouritestable which sends DB events (INSERT,MODIFY,REMOVE) to a Lambda function. -
We implemented the Lambda function to do the following:
- Receive a batch of events
- Filter the relevant events (we only need
INSERTandREMOVEevents) - Calculates how many favourites each restaurant has increased/decreased by
- Atomically increases/decreases the
favourite_countfor the restaurant by updating theAggregatedFavouritestable in an isolated transaction
Implementation Details
Atomic Updates
Multiple Lambda functions could be running at the same time so it’s important that favourite_count is updated atomically to prevent a race condition. This is done using an an update expression, but instead of using the SET action, we use the ADD action.
Lambda Retry Strategy
An ‘event source mapping’ is configured to read from our DynamoDB stream and invoke the Lambda function. We have it set so that it only sends up to 100 events to the Lambda function per invocation, and if the Lambda function fails, we’ll retry up to 20 times before the events are sent to a dead-letter queue. In addition, the batch of events gets bisected on every retry.
Transactional Updates
The Lambda function receives a batch of events and may have to update the favourite_count for multiple restaurants on each Lambda invocation. However, DynamoDB does not support a batch update function. Hence, we are making use of DynamoDB Transactions to ensure that the batch of events is never partially processed (if the Lambda has an error halfway).
Pros & Cons of This Design
| Pros 🙌 | Cons 🤷 |
|---|---|
|
|
Results
Our Lambda is invoked approximately 7k times per day. The average Lambda duration is 25ms and the average memory usage is 64MB. This means that this aggregator has a very minimal cost of < $1 per month.
There was also no significant amount of load added to DynamoDB.
So far, this system has been working very reliably and it’s been great to have aggregated data which is aggregated in real-time which has opened the door for a few interesting projects.
Alternative Designs Considered
Daily Full-Table Scan
We could have done a daily (or even weekly) full-table scan of the Favourites table. In this case, the aggregate data would no longer be realtime, which was fine for our use cases. However, we have millions of items in the Favourites table and doing so would have been expensive, so we didn’t pursue this option.
Synchronous Instead of Asynchronous Aggregation
Instead of using a DynamoDB Stream + Lambda to aggregate the data, we could have done all the logic from the Lambda in the Golang service (in the SaveFavourite/UnsaveFavourite API handler).
- Pros: Less complex (as we wouldn’t need a Lambda)
- Cons: Increased API latency, increased risk of API bugs & downtime
For us, decoupling the aggregation from the API handler was important so that’s why we didn’t pursue this option.
Seeding the Aggregated Data Table & Keeping It In-Sync
The aggregate table was seeded using a once-off script that did a full-table scan on Favourites.
We first considered this approach:
- Do a full-table scan on
Favourites - Maintain a map of restaurant id -> favourite count
- Update the
AggregatedFavouritestable
Running this script could potentially take a few hours. If our users are busy favouriting/un-favouriting restaurants during this process, this could result in the seed data being very stale by the time the once-off script updates the DB.
Although we can, we did not want to disable the ability to favourite restaurants while seeding the AggregatedFavourites table.
Instead, what we did is iterate over each of our restaurant ids, and then for each restaurant we:
- Used a scan to sum up just that restaurant’s favourite count
- Update the aggregate table
Scanning the table for just 1 restaurant is much faster (a few minutes) which means that the seed data is very unlikely to be stale.
The seed script processed restaurants concurrently and took just under 1 hour to run, aggregating a few million Favourite items in total.
We are still considering running this script on a schedule (every week or so), just in case the data in AggregateFavourites ever gets out of sync.
Conclusion
I had a lot of fun working on this aggregator - I hope you found this post helpful. If you’re interested in working at Deliveroo, please visit our careers page, and also check out @DeliverooEng on Twitter.
About Michael Seymour

I’m a Senior Software Engineer working in the consumer-side of Deliveroo. I’m primarily focused on backend and spaces > tabs ¯\_(ツ)_/¯