The road to running Apache Flink applications on AWS KDA
In this blog post, we will share the lessons we’ve learnt to run our Apache Flink applications on AWS KDA, a managed Apache Flink service.
 Squirrel on the road to reach the cloud - DALL-E
Squirrel on the road to reach the cloud - DALL-E
Table of Contents
What is Apache Flink?
According to the official documentation , Apache Flink is:
a framework and distributed processing engine for stateful computations over unbounded and bounded data streams.
That sentence is heavily packed with technical terminology. Let’s unpick them one by one.
Framework
Like other streaming frameworks, Apache Flink provides abstractions such
as source, sink and operators such as filter, map and flatMap.
Additionally, there are connectors to well known technologies such as Apache
Kafka, AWS Kinesis Stream, AWS S3, ElasticSearch and many more.
Distributed processing engine
An Apache Flink cluster is made up of a Job Manager and multiple Task Managers. The Job Manager coordinates the Task Managers and manages their resources. An application is a job that can be submitted to the cluster via the Job Manager, which in turn, gets distributed to be run on the Task Managers.
Stateful computations
It means that events can be aggregated into a state store before being emitted downstream.
Unbounded and bounded data streams
This simply means streaming and batching respectively. Streaming is the first class citizen in Apache Flink, however, it can also handle batching by treating batching as a stream that has an ending (bounded).
Why do we use Apache Flink?
At Deliveroo, we use Apache Kafka heavily for inter services communication and for analytics purposes. We have a lot of use cases where Kafka messages need to be enriched such as merging Kafka topics or to calculate user interaction sessions for analytics. Using Apache Flink enables us to solve these use cases in a repeatable way, using a vendor independent and production-ready technology.
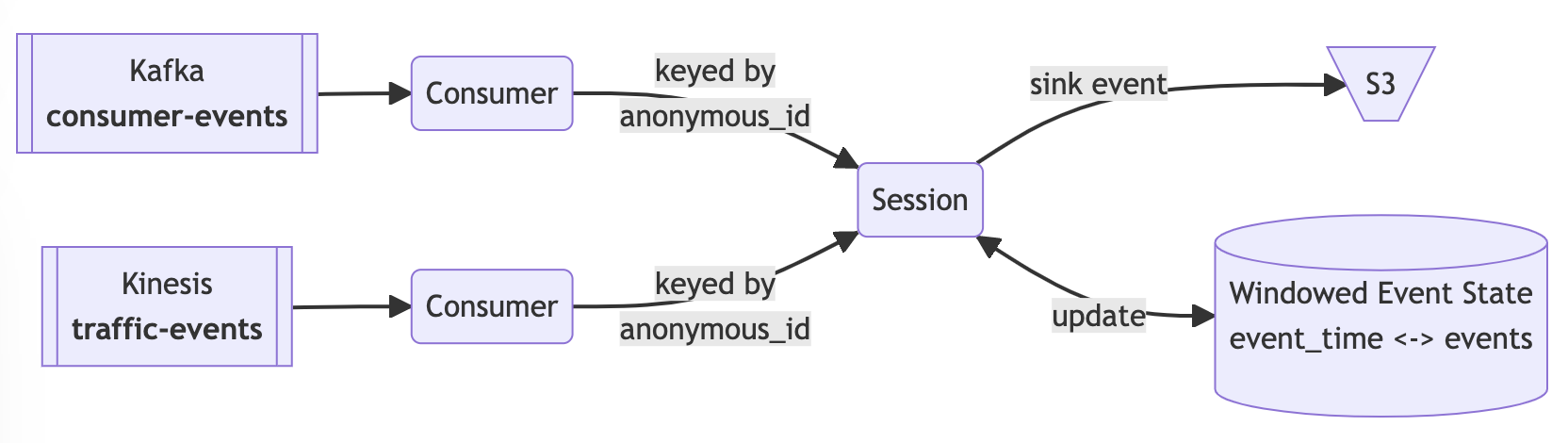
What is AWS KDA?
Amazon Kinesis Data Analytics is managed Apache Flink on AWS. It allows Apache Flink applications to be run in application mode , abstracting away the complexity of managing Apache Flink clusters.
Why did we choose AWS KDA?
Apache Flink supports a wide range of deployment environments, including standalone, kubernetes and YARN . It is also provided by cloud vendors such as AWS, AliCloud and Cloudera. Out of these options, either using AWS KDA or self managing on a Kubernetes cluster (AWS EKS) stood out the most. We chose to use AWS KDA because it abstracts and simplifies the management and operation of Apache Flink cluster. To run on AWS KDA, applications are restricted to use streaming mode, RocksDB for state backend and resources of a cluster such as CPU and memory are abstracted as KPU . These work for us as our use cases meet these requirements. As Apache Flink adoption within the organisation is still low, choosing AWS KDA is a low risk decision for us as we don’t need to rely on other teams or manage Apache Flink clusters ourselves.
What have we learnt?
Lesson 1 - The good stuff 👍
Deployment
Deploying an Apache Flink application on AWS KDA is straightforward. It is
very similar to deploying an AWS Lambda. The code artifact needs to be packaged
into a jar file (for Java) or a zip file (for Python). The artifact then
gets uploaded to S3 and the AWS KDA application needs to be pointed to that S3
object. We use the combination
of terraform resource
,
Docker multi-stage builds
and CircleCI to automate our CICD pipelines.
Flink Dashboard
Once an Apache Flink application is deployed and running, AWS KDA provides the publicly accessible ( read-only) Flink Dashboard which gives access to powerful tools such as flame graphs for debugging backpressure.
Out-of-the-box metrics
In addition to Apache Flink metrics, AWS KDA provides additional metrics for AWS MSK (Kafka) and AWS Kinesis Stream. These metrics include lag, commit success and failure counts. All metrics are available in CloudWatch.
Lesson 2 - PyFlink 🐍
Apache Flink supports Java, Scala and Python. Python support is via a library called PyFlink. We have both Java and Python Apache Flink applications. This is due to language preferences across different teams. Working with PyFlink was challenging in Apache Flink 1.13 as PyFlink was fairly new and 1.13 was the latest version that AWS KDA supported at the time (it is 1.15 now).
PyFlink internally uses py4j, it allows Python programs to communicate with the JVM via internal network, much like how PySpark does, providing Python APIs on a JVM framework. As a result, some Python APIs are not native, they are wrapper that internally call Java APIs. For example, deserialisation from Kafka consumer for Protobuf is easier to implement and more performant in Java, we then use PyFlink to wrap this Java implementation in our Python applications. Hence, our Python applications have a Java dependency.
Packaging
Packaging up a PyFlink application to work with AWS KDA was challenging for us, mainly because of the lack of documentation. But overall, our PyFlink application’s build is much more complicated than our Java applications. We use Docker multi-stage builds to build a Java library, bridging the gap between Python and Java APIs as mentioned earlier. The Java library gets packaged into a jar file and bundled with the build of our PyFlink projects.
Testing
Testing with PyFlink was also challenging. Apache Flink 1.13 was the latest
supported version on AWS KDA which didn’t come with support for testing Python,
some of the test utilities were private. We relied
on pyflink-faq repository
to get our PyFlink code tested, with the cost of copying test_utils.py into
our code base. Generally, we find that testing in Flink is quite awkward in some
scenarios which we will go into details in the next section.
Custom Metrics
In Java API, custom metrics can be easily added to any RichFunction, for
example, RichFilterFunction or RichMapFunction . This is because the custom
metric requires access to RuntimeContext , which is provided
from void open(Configuration config) method. However, in PyFlink, even though
all methods extend pyflink.datastream.Function which has an open method,
from our experience, it doesn’t always work. For example, we cannot get a custom
metric to work with FilterFunction function in PyFlink. As a workaround, we
need to use MapFunction instead, handle custom metric logic within the map
function and let the value pass through:
def map(self, event):
if not has_mandatory_fields(event):
self.custom_metrics[MISSING_MANDATORY_FIELD_METRIC_KEY].inc()
elif not is_valid_timestamp(value):
self.custom_metrics[INVALID_TIMESTAMP_METRIC_KEY].inc()
return event
JVM ↔ Python VM Gotcha
PyFlink comes with a cost of resources on task managers because each task manager needs to spare some of its resources (CPU and RAM) for Python. The resources which usually can be fully used by JVM, are now shared. AWS KDA has a default limit of 32 KPU per application where 1 KPU is equivalent to 1 vCPU and 4 GiB of memory. Having to share these resources required us to run some of our applications at a larger scale, compared to running in Java.
Lesson 3 - Development and Testing 🏗️
We use Apache Flink streaming API exclusively because the stream DSL is more familiar to us and also gives us access to low level functions such as the process function . Our main application becomes self descriptive and very readable, for example:
valid_kafka_event_src.union(valid_kinesis_event_src)
.key_by(key_selector, key_type=Types.STRING())
.flat_map(BotTagEnrichment(), output_type=bot_event_output_type_info)
.uid(OP_BOT_TAGGING)
.name(OP_BOT_TAGGING)
.sink_to(bot_tagging_sink)
.uid(SINK_BOT_TAGGING_S3)
.name(SINK_BOT_TAGGING_S3)
However, testing in Apache Flink can be cumbersome. Specifically, to test an operator’s logic, source(s) and sink(s) can then be stubbed, allowing inspection on the operator’s input and output; however, a mini cluster needs to be spun up in memory. This makes the tests very slow because the cluster needs to be warmed up and teared down. Additionally, with limited resources while running these tests locally or in a CI environment, tests can only be run sequentially.
event_src = self.env.from_collection(events, type_info=input_type_info)
event_src
.key_by(key_selector, key_type=Types.STRING())
.flat_map(BotTagEnrichment(), output_type=bot_event_output_type_info)
.add_sink(self.test_sink)
.name(str(uuid.uuid4()))
self.env.execute()
In the snippet above, the source is stubbed with static data from a list of
events and the sink is a test_sink . By running the static events through
the BotTagEnrichment operator, we can collect its output from the test_sink
and compare it with our expectation. self.env.execute() is to run the
application on the mini
cluster.
Lesson 4 - The Missing Pieces 🧩
Even though AWS KDA is a managed Apache Flink service, it is not perfect and there are gaps that we need to fill.
- A snapshot (save point) is automatically created on stopping the application. However there isn’t a way to schedule creation of snapshots (and cleaning them up).
- Code artifacts are stored in S3 and are required to be there for versioning purposes, for example, if we need to revert to a previous version of the app. However, over time, these artifacts will need to be pruned as they can get quite big.
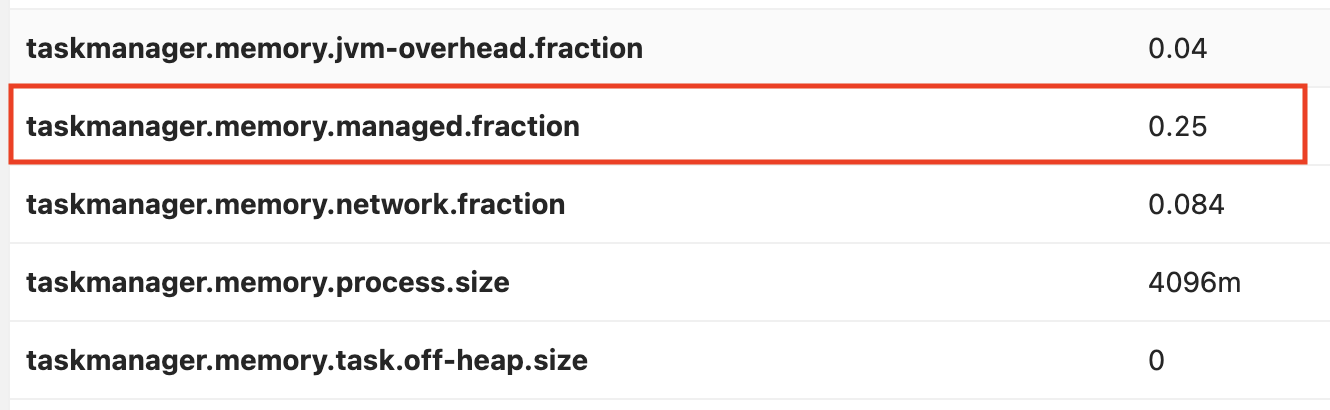
- Low level configs for task managers are hard to change. For example, PyFlink
application requires more managed memory. Managed memory is configured
by
taskmanager.memory.managed.fraction, which is0.4by default, however, this config is0.25in KDA. A support ticket needs to be raised with AWS to get this config changed if we want to reserve more memory for PyFlink. Additionally, the custom config cannot survive application restart, for it to be applied automatically between restarts, further AWS support ticket is required.
- The concept of KPU and parallelism can be confusing and hard to configure. For
example, application A of
40 Parallelism / 2 ParallelismPerKPU = 20 KPUand application B of40 Parallelism / 6 ParallelismPerKPU = 7 KPU. From the screenshots below, we can see that differentParallelismandParallelismPerKPUcan result in different number of task managers with different resources allocation. HigherKPUand lowerParallelismPerKPUgives us fewer task managers, but each of them have hefty resources (CPU and RAM), whereas lowerKPUand higherParallelismPerKPUgives us many small task managers. The nonlinearity of physical resources under the hood makes the KPU abstraction less useful.
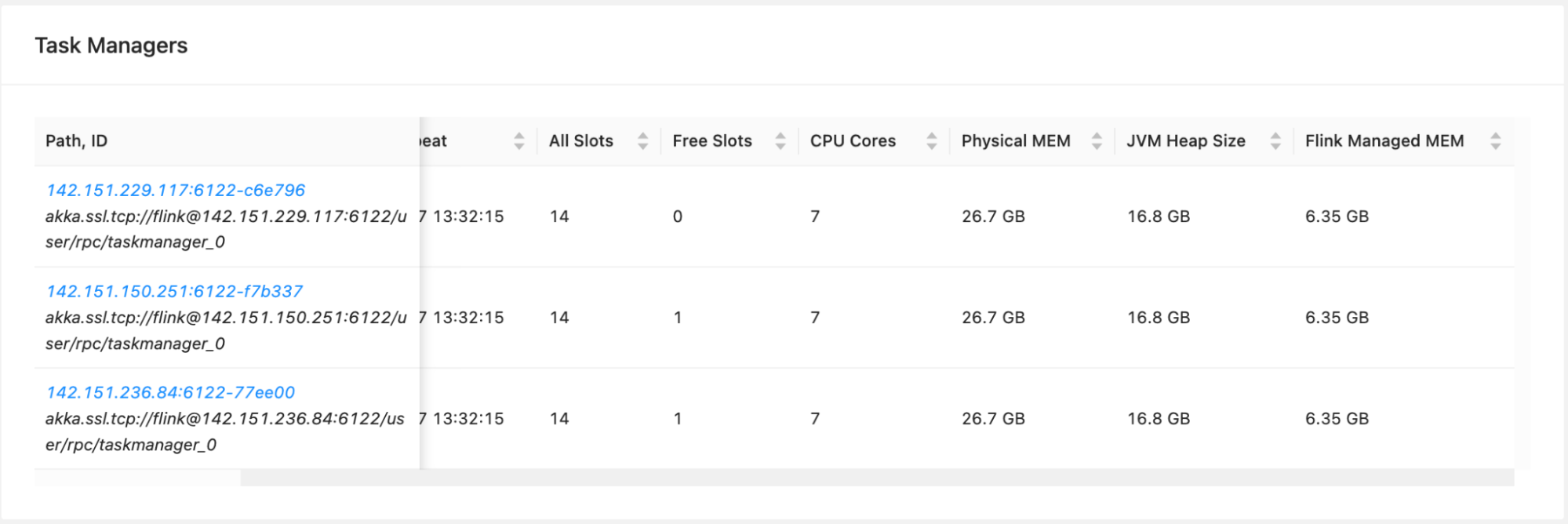
Application A - 20 KPU
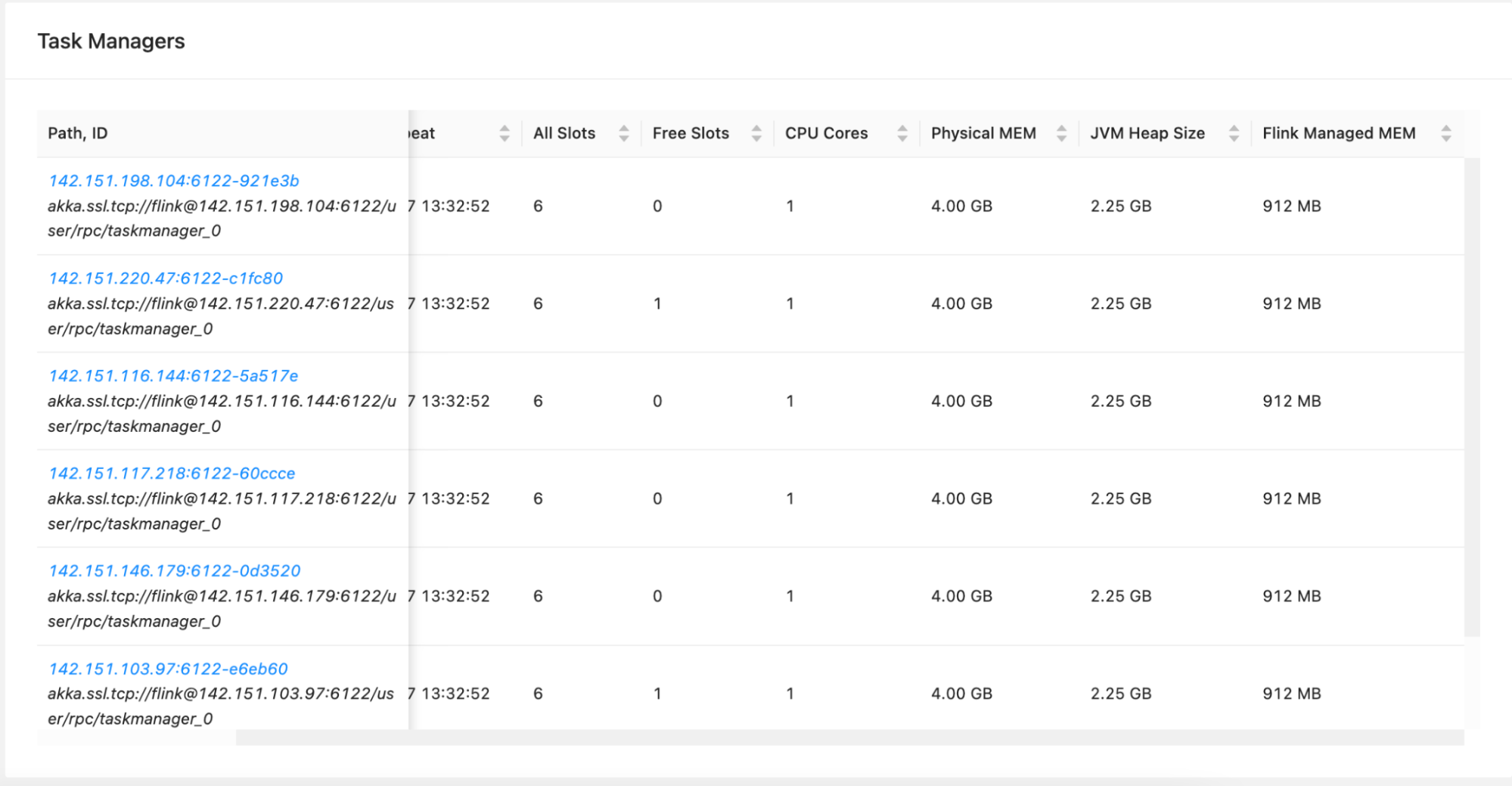
Application B - 7 KPU
Conclusion
The road to run Apache Flink applications on AWS KDA was quite rocky. However, it has been improved since we started:
- Documentation and tutorials have been updated
- Apache Flink 1.15 has been released on AWS KDA
- Lots of bugs have been fixed
Looking back, we are happy with our decision of using AWS KDA. This helps us to focus on ramping our Apache Flink knowledge without worrying about managing Apache Flink clusters. AWS KDA, like other AWS managed services might not be for everyone. It is an opinionated approach of running Apache Flink clusters. It is good for new Apache Flink adopters, or for small to medium size applications. For large applications which require resources customisation, or small applications which can benefit from sharing an Apache Flink cluster (session mode), AWS KDA might not be the most cost effective or the most flexible choice.
Our next mission is to make Apache Flink even easier to work with, in order to drive its adoption within Deliveroo. Please stay tune for more Apache Flink blog posts!
About Duc Anh Khu

I’m a senior software engineer, my current focus is on streaming technologies. At Deliveroo, I write code to help teams to move data from one place to another efficiently.